Introduction:
Word cloud is a visual representation of text data. Word cloud is also known as text cloud or tag cloud. Word cloud is used by researchers for reporting qualitative data. Marketing makes use of word cloud in order to understand customer feed back on product features and customer pain points. Journalists and social media resort to word cloud to understand the sentiments of the public towards political personalities or on some important social issues.
Oxford English Dictionary defines word cloud as "an image composed of words used in a particular text or subject, in which size of each word indicates its frequency or importance".
Word cloud is a simple and elegant way of text analysis. In simple terms, word clouds simple, easy to make and fun. It is very useful in understanding a particular subject on which textual data is available. Word cloud is text mining in the most simple form.
Many online word cloud generators exist and the prominent ones are:
1. WordArt
2. WordClouds
3. WordCloudMaker
4. WordSift
5. ABCya
6. JasonDavies
7. MonkeyLearn
8. WordItOut
The above listed online word cloud generators are free. However, some of the online word cloud generators require the user to subscribe and make payment for certain additional facilities like downloading word cloud image or word tokens.
Word cloud applications:
1. Analysis of customer feed back on the products.
2. Authors of books could use word cloud for checking whether the book has given enough importance for the protagonist or the main theme of the book.
3. An overall sentiment about leaders or schemes could be understood through word cloud or sentiment analysis.
The R is a software with its word cloud package is very much capable of handling text data for making word cloud. The online word cloud generators provide a more user friendly interface for the customer. While, if you prefer R for making word cloud, you need to write a little bit of coding. This requires a good knowledge of the R language. Word cloud made with R could be saved in pdf, PNG, BMP, TIFF, and JPEG formats. R word cloud images made with proper specification of coding would be of professional and publication quality in general.
R is a language and environment for statistical computing and graphics. R is an open source software available free. R is very suitable for research oriented statistical analysis. The R provides a platform for developing professional publication quality graphics.
The steps involved in developing a word cloud involves the following steps:
1. Data collection and storing the text data so collected in either csv or text file format.
2. Cleaning the data for removing punctuation, numbers, symbols, etc.
3. Making a corpus and document term matrix for making the word cloud.
4. Displying the word cloud made with wordcloud package and function in R.
The prima facie assumption and expectation from the reader is a good familiarity with R and RStudio. I have used R3.6.3 for running the word cloud code for this booklet. If you have R software already installed on your computer, it is fine. Other wise, download the latest version of R software available in R-CRAN foundation website (the link has been given in the reference) and install it on to your desktop or laptop computer. The latest version available as on 24/04/2021 is R4.0.5
The two examples have been considered in the following chapters for demonstration on how to form a word cloud on text data. Example 1 makes the word cloud on text data obtained from the responses on COVID-19 responses on social media. The second example demonstrates how to form a word cloud on text data in a pdf file. I have considered my book on "Supply Chain Management by Arunachalam Rajagopal" in Amazon Kindle platform.
Example1: Word cloud on COVID-19 responses
In Example 1, Word cloud has been made with chat responses on COVID-19 by users of facebook and twitter. The necessary R-code has been given below in Table 1.
Table 1 R-code for COVID-19 wordcloud
#--------------------------------------------------------------------------------------
library(NLP)
library(tm)
library(RColorBrewer)
library(SnowballC)
library(wordcloud)
reviews<-read.csv(file.choose(), sep=",", header=T)
review_text<-paste(reviews$text, collapse="")
#paste converts its arguments (via as.character) to character strings, and concantenates them
#---------------------------------------
abc<-review_text
abc<-removeNumbers(abc)
abc<-removePunctuation(abc)
abc<-tolower(abc)
abc<-removeWords(abc,c("now", "one", "will", "may", "says", "said", "also", "re"))
stopwords<-c("the", "and", "can", stopwords("en"))
abc<-removeWords(abc, stopwords("en"))
abc<-stripWhitespace(abc)
review_text<-abc
#---------------------------------------
review_source<-VectorSource(review_text)
#A vector source interprets each element of the vector as a document
#Next step: to make a corpus
corpus<-Corpus(review_source)
#Next step: Document-term matrix
dtm<-DocumentTermMatrix(corpus)
dtm2<-as.matrix(dtm)
frequency<-colSums(dtm2)
frequency<-sort(frequency, decreasing = T)
head(frequency)
words<-names(frequency)
#Visualization of the data
plot(frequency)
#visualization via wordcloud package
wordcloud(words, frequency, max.words=50, random.order=FALSE, rot.per=0.25, colors=brewer.pal(3,"Dark2"), scale = c(4,0.5))
#--------------------------------------------------------------------------------------
The packages NLP, tm, RColorBrewer, SnowballC, wordcloud are to be loaded into the R active environment. This is achieved by the library(x) function, x stands for the name of the package to be loaded. If any of these packages is not available in your R platform, then use the following R code for installing the particular package.
instal.packages("tm")
R code for installing tm library is given above. Similarly, other required packages could also be installed on to your R platform.
The text responses in the file named corona_30052020 has been input into R using read.csv function.
read.csv(file.choose(), sep=",", header=T)
The file.choose() command allows the user to read in the csv file from any convenient file location in your computer. The Figure 1 shows the file input with text data.
Figure 1 Text data input file
Otherwise you can also use the following code for data input.
reviews<-read.csv(corona_30052020.csv, sep=",", header=T)
The csv file is in comma separated format and this is indicated by sep="," and header=T or header=TRUE argument indicates that the first line in the csv data file is the title line or header line which indicates the column names.
Next step is to join all the words in the input file into one single character string through concatenation by using paste function as shown below. The words when converted into a single character string enables cleaning function easier.
review_text <- paste(reviews$text, collapse="")
The Figure 2 depicts the cleaning functions used on the text data.
Figure 2 Cleaning the text data
The cleaning of the text data is achieved through functions such as remove Numbers, and removePunctuation. The stop words are removed using removewords function. The command line given below demonstrates usage of remove words function. Stop words usually refer to the most commonly used words like "the", "an", "and", etc. In text analysis the stop words do not add much value and have no significance. Hence, the stop words are removed for carrying out text analysis like word cloud.
abc <- removewords(abc, c("now", "one", "will", "says", "said", "also", "re"))
This command line removes words such as "now", "one", "will", "says", "said", "also", and "re". These are words which you do not want to appear in the word cloud. The code given below adds three words temporarily into the stop words list by the command line given below.
stopwords <- c("the", "and", "can", stopwords("en"))
Then the command line that appears below removes the stop words from the character string 'abc' and stores it back to 'abc'.
abc<- removewords(abc, stopwords("en"))
The unnecessary white spaces in the character string made from the responses on COVID gets removed by the command line shown below.
abc <- stripWhiteSpace(abc)
The next step is to make the corpus and document-term-matrix. This is achieved by the R code given below.
#---------------------------------------
review_source<-VectorSource(review_text)
#A vector source interprets each element of the vector as a document
#Next step: to make a corpus
corpus<-Corpus(review_source)
#Next step: Document-term matrix
dtm<-DocumentTermMatrix(corpus)
dtm2<-as.matrix(dtm)
frequency<-colSums(dtm2)
frequency<-sort(frequency, decreasing = T)
head(frequency)
words<-names(frequency)
#---------------------------------------
First of all, a vector source is made from the cleaned character string. Then, a corpus of the words in the form of vector source is made. The corpus of words is then converted into document-term-matrix. The Figure 3 shows the corpus and document-term-matrix formation.
Figure 3 Corpus and dtm
The R code displayed finds the frequency for each of the words in the document term matrix and arranges in terms of descending order of frequency. The words frequency could be visualized by the R-code: plot(frequency). The Figure 4 shows the plot of frequency for the text data.
Figure 4 plot of frequency for the textdata
The final step is the word cloud visualization and display. The wordcloud function is provided with the words and the corresponding frequency for formation of the word cloud in this example. The wordcloud function could as well be provided with the 'corpus' of the words. Then, also the function will successfully form and display the word cloud. The other arguments could also be passed on to the wordcloud function for further customization of the wordcloud display. For example max.words=50 limits the number of words displayed in the word cloud. The argument random.order=FALSE ensures that the colours are assigned based on the frequencies; other wise, colours will be assigned randomly to the words displayed in the word cloud. The argument colors = brewer.pal(3,"Dark2") specifies the colours to be used in the word cloud and scale(4,0.5) indicates the range of font sizes to be used for the words display in the word cloud. The Figure 5&6 display the word cloud for the text data on covid responses.
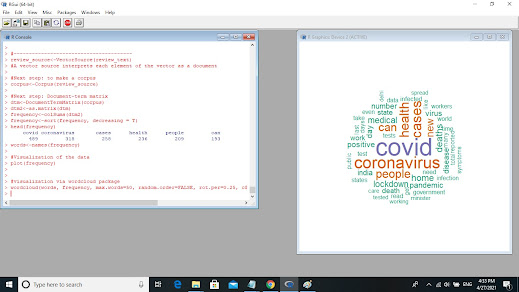
Figure 5 Worcloud in the R console
The Figure 6 depicts the word cloud in JPEG format.
Figure 6 wordcloud on COVID-19 responses from facebook and twitter
First example has formed word cloud on
COVID-19 responses on social media. The size of word in a word cloud indicates
its importance in terms of its frequency of occurrence in the text data. Larger
the word size, more frequent is the word appearing in the text data. The words
like covid, coronavirus, people, health, cases are the most prominent ones at
first sight of the word cloud. The next in line in terms of font size are the
words like lockdown, home, pandemic, deaths, positive, disease, medical,
number, and india.
The simple text analysis tool like
word cloud indicates the main issue clearly (covid, coronavirus, people,
health, and cases). Word cloud has also brought out clearly matters of concern
related to the pandemic (lockdown, home, pandemic, deaths, ...). It is worth
noting that there are no negative sentiments or anger expressed on the
administration in the social media. This possibly indicates that the government
has performed fairly well.
Example2: Word cloud on book in pdf
In Example 2, Word cloud has been formed for my book on "Supply Chain Management". The book in pdf format has been provided as the input for making word cloud. The library(pdftools) is the additional package to be activated for this word cloud example. The difference in the R code between Example 1 and Example 2 is only inn the file input section. Other wise, R code for both the examples are same.
Table 2 R code for wordcloud on scm book in pdf
#---------------------------------------------------------------------------------
library(NLP)
library(tm)
library(RColorBrewer)
library(SnowballC)
library(wordcloud)
#pdf file as input data for wordcloud
library(pdftools)
txt <- pdf_text(file.choose())
abc <- character()
for(i in 2:length(txt)){
xyz <- strsplit(txt[i], '\r\n')
for(line in xyz){
abc <- c(abc, line)
}
}
reviews <- data.frame(text=abc)
review_text<-paste(reviews$text, collapse="")
#paste converts its arguments (via as.character) to character strings, and concantenates them
#---------------------------------------
abc<-review_text
abc<-removeNumbers(abc)
abc<-removePunctuation(abc)
abc<-tolower(abc)
abc<-removeWords(abc,c("now", "one", "will", "may", "says", "said", "also", "figure"))
stopwords<-c("the", "and", "can", stopwords("en"))
abc<-removeWords(abc, stopwords("en"))
abc<-stripWhitespace(abc)
review_text<-abc
#---------------------------------------
review_source<-VectorSource(review_text)
#A vector source interprets each element of the vector as a document
#Next step: to make a corpus
corpus<-Corpus(review_source)
#Next step: Document-term matrix
dtm<-DocumentTermMatrix(corpus)
dtm2<-as.matrix(dtm)
frequency<-colSums(dtm2)
frequency<-sort(frequency, decreasing = T)
frequency
#Visualization of the data
plot(frequency)
head(frequency)
words<-names(frequency)
#visualization via wordcloud package
wordcloud(words, frequency, max.words=50, random.order=FALSE, rot.per=0.25, colors=brewer.pal(3,"Dark2"), scale = c(3,0.5))
#---------------------------------------------------------------------------------
The Figure 7 shows the supply chain management book in pdf being input into R platform for making the wordcloud.
Figure 7 Wordcloud on scm book in pdf
The Figure 8 shows the word cloud on SCM ebook in pdf.
Figure 8 Word cloud on SCB ebook in pdf
As has already been indicated, the
second example is on a book in pdf titled 'Supply Chain Management'. In
contrast with example 1 which was on a pandemic or a major social issue, the
example 2 deals with business concept related to effective distribution of
products and services to customer. The word cloud highlights words like supply,
chain, logistics, product, cost, material, and company in a prominent manner
with larger word size. Next comes the operational aspects of supply chain. This
is being indicated by the next lower font size words like inventory, supplier,
capacity, transport, distribution, network, order, and demand. Hence, the book
in pdf on SCM (supply chain management) appears to highlight the main theme of
the book. The tactical and operational aspects have also been brought forth in
the book fairly well. Word cloud analysis has given a result which appears
positive on my book. It is pleasing, however, a surprise of course!
References:
1. Sanil Mhatre (2020), Text Mining and Sentiment Analysis: Analysis with R
https://www.red-gate.com/simple-talk/sql/bi/text-mining-and-sentiment-analysis-with-r/
2. https://www.mydatahack.com/how-to-create-a-word-cloud-for-your-favourite-book-with-r/
3. https://cran.r-project.org/











Comments
Post a Comment